Building personal search infrastructure for your knowledge and code [see within blog graph]
Table of Contents
¶1 Why search?
However this information is not so useful if you can't access and search it quickly. Instant search changes the way you think. Ever got sense of flow while working through some problem, and trying different things from Stackoverflow or documentation?
These days, if you have decent connection, you are seconds away from finding almost any public knowledge in the internet. However, there is another aspect of information: personal and specific to your needs, work and hobbies. It's your todo list, your private notes, books you are reading. Of course, it's not that well integrated with the outside world, hence the tooling and experience of interacting with it is very different.
Some examples:
- To find something from my Messenger history with a friend, I need to be online, open Facebook, navigate to search and use the interface Facebook's employees thought convenient (spoiler: it sucks)
It's my information, something that came out from my brain. Why can't I have it available anywhere, anytime, presented the way I prefer?
To find something in my Kobo ebook, I need to reach my device physically and type the query using the virtual keyboard (yep, e-ink lag!). Not a very pleasant experience.
It's something I own and have read. Why does it have to be so hard?
Such things are pretty frustrating to me, so I've been working on making them easier. Search has to be incremental, fast and as convenient to use as possible. I'll be sharing some of workflows, tricks and thoughts in this post.
The post is geared towards using Emacs and Org-mode, but hopefully you'll find some useful tricks for your current tools and workflow even if you don't. There is (almost) nothing inherently special about Emacs, I'm sure you can achieve similar workflows in other modern text editors given they are flexible enough.
Note: throughout the post I will link to my emacs config snippets. To prevent code references from staling, I use permalinks, but check master branch as well in case of patches or more comments in code.
¶2 What do I search?
I'll write about searching in
- my personal notes, tasks and knowledge repository (this blog included)
- all digital trace I'm leaving (tweets, internet comments, annotations)
- chat logs with people
- books and papers I'm reading
- code that I'm working on
- information on the Internet (duh!)
¶3 Searching in personal information
By personal information I refer to things like todo list, personal wiki or whatever you use to store information relevant to your life.
¶Org mode notes
For the most part, I keep things in Org mode, and I use Emacs to work with it. Apart from regular means of plaintext search (I'll write about it later), for me it's important to search over tags:
org-tags-viewis available by default and an easy way to run simple tag searches-
It's a relatively new package, with new query syntax as the main feature, which is much easier to use and remember than builtin Org query syntax: comparison.
I mainly use these commands:
helm-org-qlfor incremental search in the current bufferorg-ql-searchinteractively prompts you for the search target, sort and grouping
Another notable mention is org-rifle, which is an entry based search, presenting headings along with the matched content in Helm buffer. However as the author mentioned it might be obsoleted by org-ql soon.
Here are some typical workflows with my org-mode:
-
I see an interesting article or think of something which would be good to share with a friend, but at the moment it's not quite a good time to send it. I can just capture it and attach a tag (e.g. ann or jeremy). That way next time we chat I can just look up things under their tag and send them.
It works the other way around as well: imagine they sent me a link or asked me to do something, but I can't do it immediately. I have a special script that converts chat messages into todo items and automatically attaches the corresponding tag. I write more about it here.
assembling blog posts
Unfortunately, I can't just sit and write comprehensible texts without preparation. Typically I have thoughts on the topic now and then, which I just note down and mark with the tag. When I feel it's time to prepare the post, I can just search by the tag (e.g.
tags:searchfor this post), and refile the items into the file with the post draft.
¶Other plaintext, chats and social media
As I mentioned, I find having to switch to the browser, wait till the website loads and cope with crappy search implementations very distracting and frustrating.
What is more, often you don't even remember whether exactly you were discussing something: on Telegram or Facebook or Reddit? So having a single point of entry to your information and unified search over all of your stuff is extremely helpful.
For instant messaging, I'm using plaintext mirrors, so chat history is always available in plaintext on my computers:
- Telegram messages Didn't bother with org-mode because files would be too huge and there isn't much structure anyway.
- Vkontakte messages Sadly export tool stopped working because of API restrictions, but I'm not using VK much anymore either. At least I got historic messages.
Most services where I can comment, write or leave annotation, I'm mirroring as org-mode. I write about it in detail here: part I, part II.
That gives me source data for a search engine over anything I've ever:
- tweeted
- bookmarked on Pinboard
- highlighted in Instapaper or Kobo
- saved or upvoted on Reddit
- etc., etc.
All these files are either non-Org or somewhat heavy for structured Org-mode search. In addition, I have many old files from my pre-orgmode era when I was using Gitit or Zim.
To search over them, I'm using Emacs and Ripgrep (you can read why later):
my/search
runs ripgrep against my/search-targets variable contains paths to notes, chat logs, Orger outputs etc.
The interesting bit about my/search is --my/one-off-helm-follow-mode call. It's a somewhat horrible hack that automatically enables helm-follow mode so you don't have to press C-c C-f every time you invoke helm.
Finally, to make sure I can invoke search in an instance, I'm using a global keybinding.
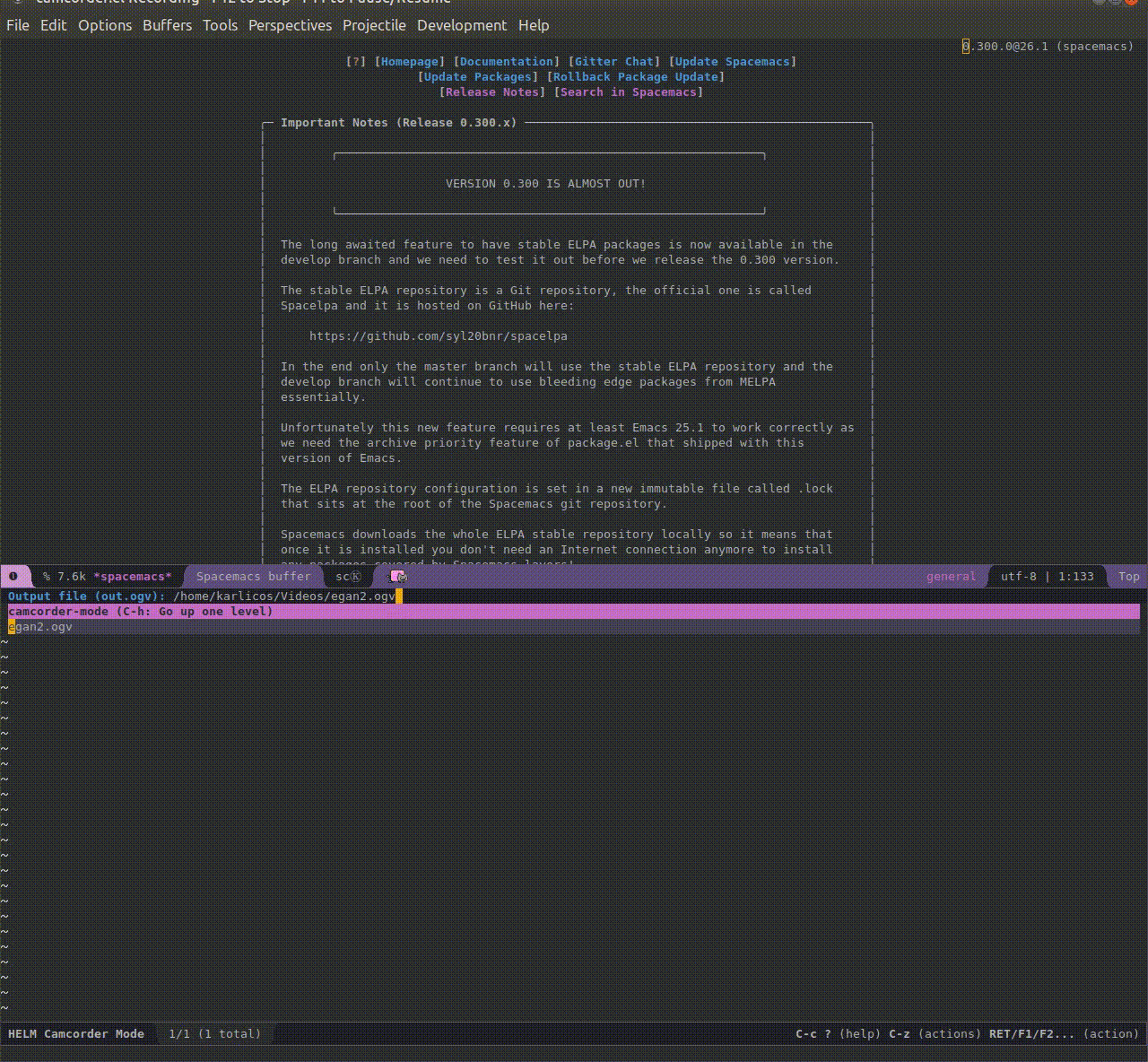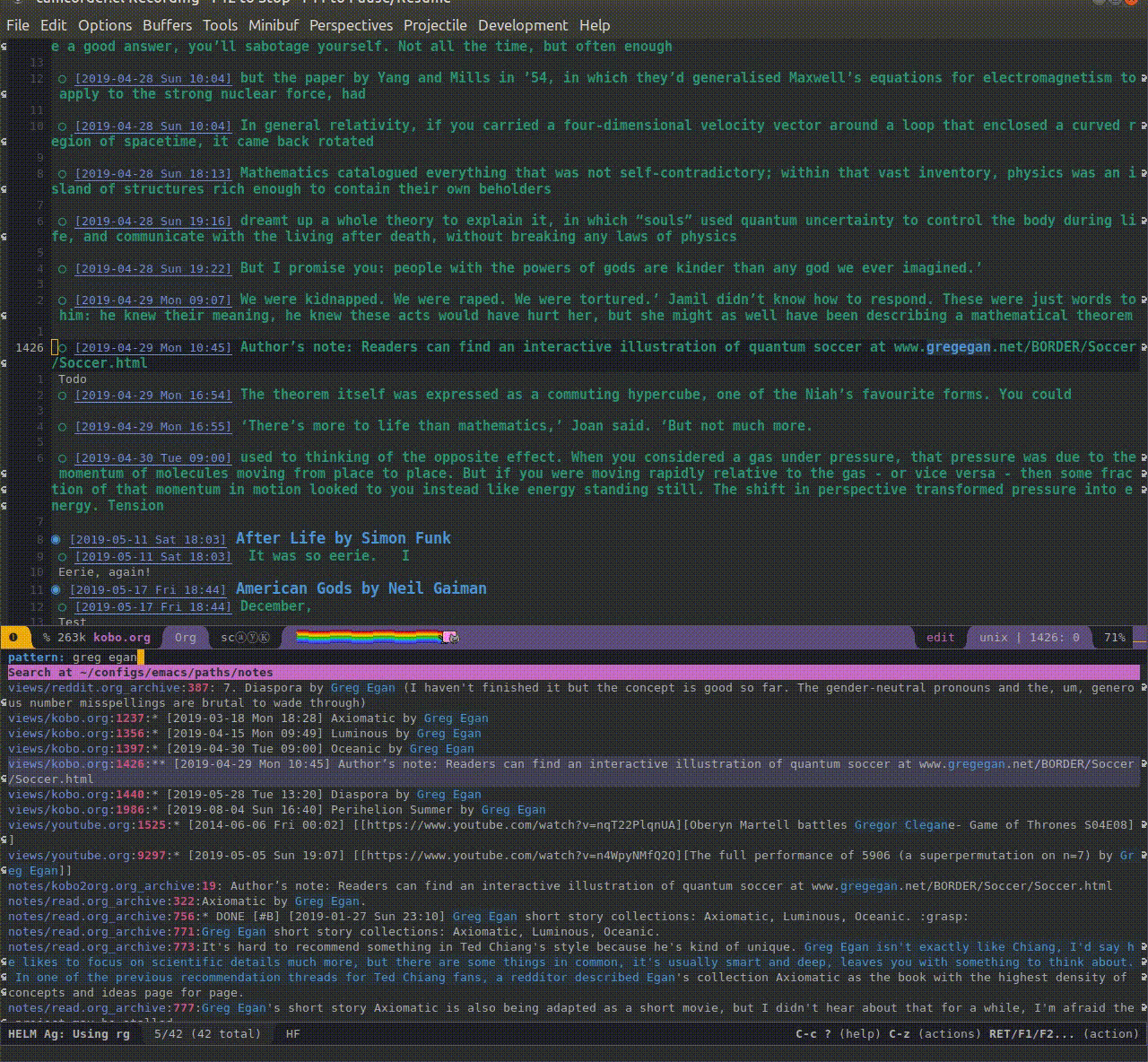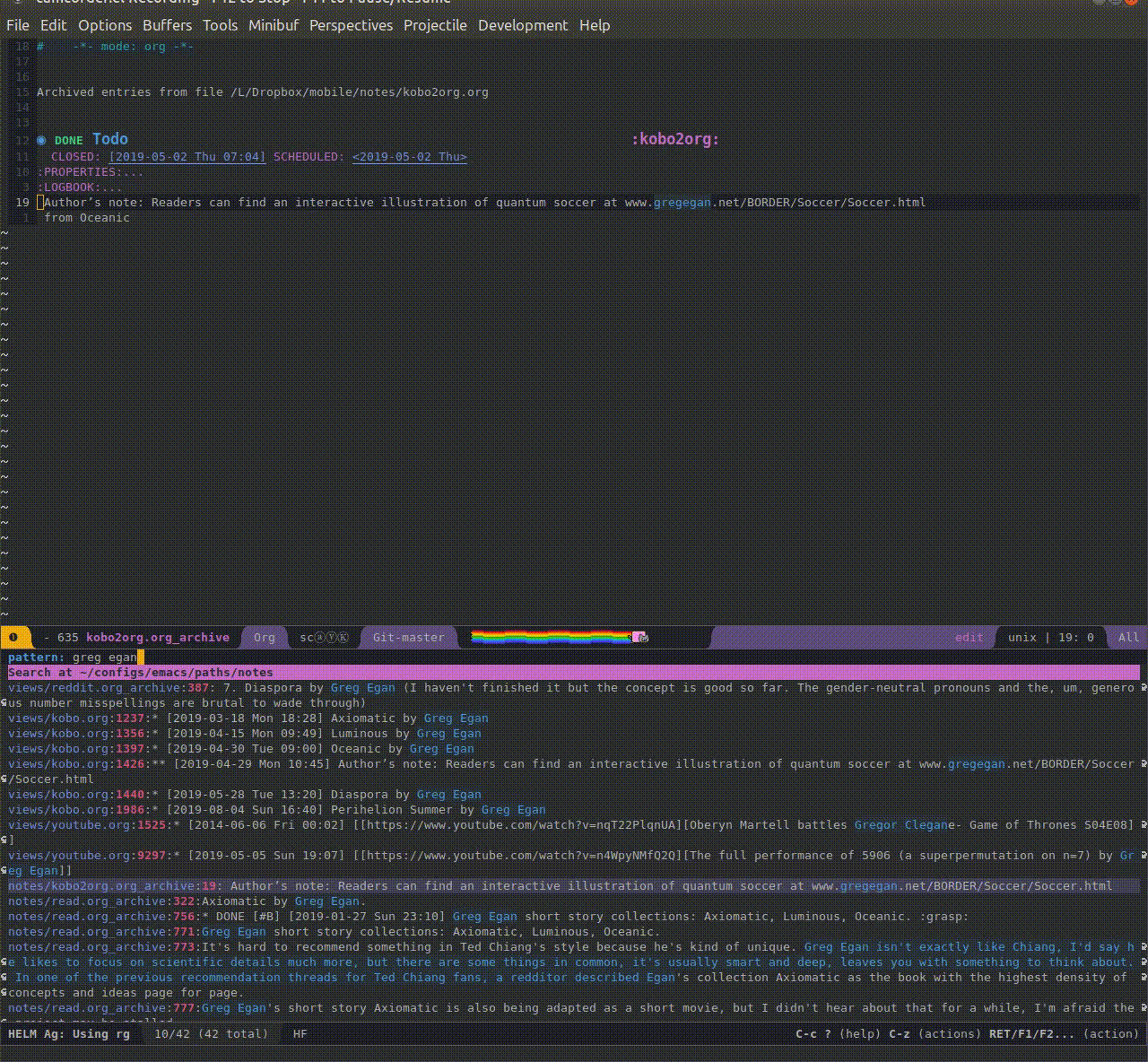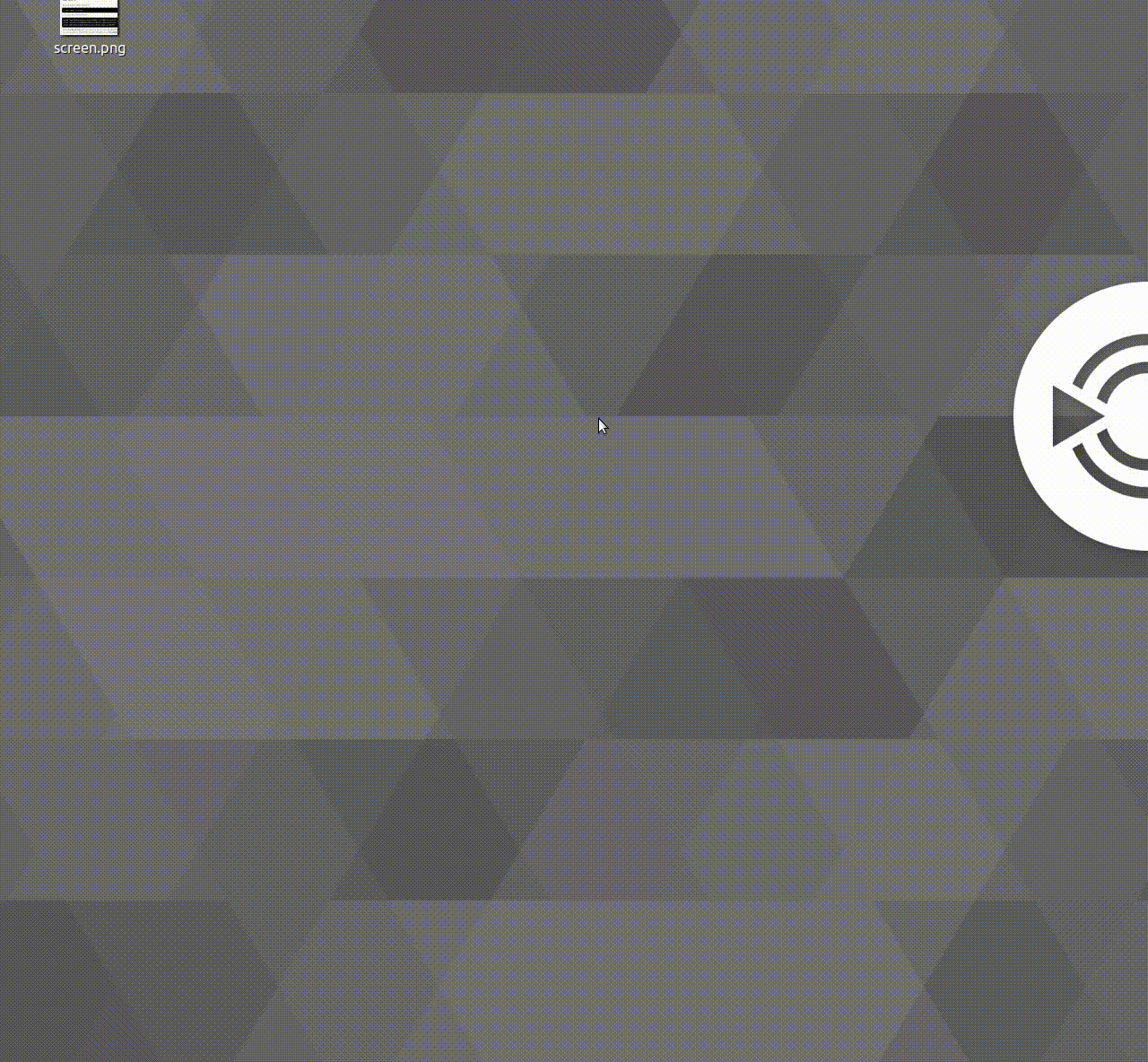
Here's a demo gif (5Mb) of using this to search 'greg egan' in my knowledge repository. You can see that as a result, I'm getting my Kobo highlights (kobo.org), my reading list (read.org) and even some video (youtube.org)!
{kind=link}
¶4 Recoll
Recoll is an indexer that runs as daemon (or a regular cron job) and a full text search tool.
It supports many formats and other features, so I suggest checking them out for yourself.
Even though I index all my documents, I find it quicker to run grep I described above to search in plaintext. So for me, Recoll is mostly for searching and quickly jumping to results in PDFs and EPUBs (see screenshot).
There is helm-recoll Emacs module, but I found it a bit awkward to use, and Recoll GUI feels significantly superior. Basically only thing helm-recoll does is presenting you list of filenames that match your query. It feels that it should be straightforward to modify the module and integrate abstract, snippets and other things you can query Recoll for.
Considering I don't need use Recoll it too often, I just gave up on helm-recoll and using GUI.
I'm also running a Web UI on my VPS, so I can use it from my phone, or potentially from other computers.
Recoll's distinguishing features are proper search query language and realtime, inotify based indexing. I don't have that much data yet to benefit massively from proper search queries, but I can see that it could be potentially useful in future as amount of personal data grows.
¶5 Searching on Android
Most of my notes and knowledge repository are plaintext, so it is easily and continuously shared on my phone via Dropbox/Syncthing.
Since using Emacs on Android is hardly a meaningful experience, I'm working around it by using other apps.
¶Orgzly
I can't recommend it enough, it's got many things done right, very fast and the code is extremely readable and well tested so it's easy to contribute.
It has its own small query language (at the time org-ql didn't exist).
You can save search queries, which ends up being pretty similar to custom Org-mode agendas.
Searches can be displayed as persistent widgets, e.g. I find convenient to have a phone screen dedicated to 'Buy' search (t.buy query) or 'Do at work' search (t.@work query).
As I described above, I keep few saved search queries for some friends so I can recall what I wanted to discuss with them.
¶Docsearch +
Docsearch is a not very well-known tool (e.g. zero search results on Reddit or Twitter), but I don't know any alternatives for it.
It's a fulltext indexing and search app for plaintext files, but apparently it even supports EPUBs and PDFs. Here's how matches list looks. Screenshots on Google Play give a pretty good idea what the app does.
I find it convenient for quick search over things that are not imported in Orgzly, e.g. .txt chat logs (Telegram, VK) and huge org-mode files I described above.
It's a bit backwards in terms of UI (even though I like that it's compact and functional), but main downside is it's not opensource. I'd be extremely happy to replace this with some open source application, so please let me know if you know one!
¶6 Web search
If you're reading this at all, chances you're quite good at using web search already. Gwern got a good writeup on the subject.
Knowing how to compose a search query is one thing, but navigating to the service, waiting till it loads, moving to searchbox takes precious time. Many people forget about custom search engines. Here are ones I'm using:
| g | https://www.google.com/complete/search?client=firefox&q={searchTerms} |
|
| d | DuckDuckGo | https://duckduckgo.com/?q={searchTerms}&t=canonical |
| r | https://www.reddit.com/search?q={searchTerms} |
|
| gh | GitHub | https://github.com/search?q={searchTerms}&ref=opensearch |
| pin | Pinboard: search all | https://pinboard.in/search/?query={searchTerms}r&all=Search+All |
| tw | https://twitter.com/search |
|
| hn | hackernews | https://hn.algolia.com/?dateRange=all&page=0&prefix=true&query={searchTerms}&sort=byPopularity&type=all |
| y | YouTube | https://www.youtube.com/results?search_query={searchTerms}&page={startPage?}&utm_source=opensearch |
| m | Google Maps | https://www.google.com/maps/search/{searchTerms}?hl=en&source=opensearch |
| w | Wikipedia (en) | https://en.wikipedia.org/wiki/Special:Search |
| tl | Google Timeline | https://www.google.com/maps/timeline?pb=!1m2!1m1!1s{searchTerms} |
| cpp | Cppreference | https://en.cppreference.com/mwiki/index.php?search={searchTerms} |
| js | MDN | https://developer.mozilla.org/en-US/search?q={searchTerms} |
| eb | Ebay | https://www.ebay.co.uk/sch/i.html?_nkw={searchTerms} |
| am | Amazon.co.uk | https://www.amazon.co.uk/exec/obidos/external-search/ |
| th | thesaurus | https://www.powerthesaurus.org/{searchTerms}/synonyms |
| tru | Translate en-ru | https://translate.google.com/#view=home&op=translate&sl=en&tl=ru&text={searchTerms} |
| tde | Translate en-de | https://translate.google.com/#view=home&op=translate&sl=en&tl=de&text={searchTerms} |
| dd | DevDocs | https://devdocs.io/#q={searchTerms} |
| em | emoji | https://emojipedia.org/search/?q={searchTerms} |
Some of these obvious, some deserve a separate mention:
reddit contains vast amounts of (somewhat curated) human knowledge
Google search often gives dubious and not very meaningful results on certain topics (e.g. product reviews, exercise, dieting). On reddit, you'd at least find real people sharing their honest and real opinions. Chances are that if a link is good, you would find it on on reddit anyway.
twitter is similar: there is certainly more spam there, but sometimes it's interesting to type a link or blog post title in twitter search to see how real people reacted.
That has limited utility, e.g. doesn't work with politicized content, but if the topic of interest is rare, could be very useful.
- hackernews: good source of knowledge and high quality discussions for tools and tecnhologies
- pinboard is an awesome source of curated content as well
Next, I find it very convenient to have some code documentation available locally. First, it helps when you're on wonky internet or just offline for whatever reason. Second, it's feels really fast, even if you're on fiber.
Here's what I'm using for that:
| py | file:///usr/share/doc/python3/html/search.html?q=%s |
| rust | file:///home/karlicos/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/share/doc/rust/html/std/option/index.html?search=%s |
Sadly, the extension mentioned above doesn't work with file:// schema for some reason, so to add it in Firefox, you can use the method described here, it's as easy as adding a bookmark.
Recently I ran into devdocs.io, it's using your browser's offline storage to cache the documentation.
I'm still getting used to it, but it's amazing how faster it is than jumping to documentation online. You can use it with multiple languages, you just type the search engine prefix first, and then language prefix (e.g. dd cpp emplace_back).
Finally, it may be convenient to set up engine-mode in Emacs, or search-engine layer in Spacemacs. It lets you invoke a browser search directly from Emacs (e.g. SPC s G to do google search). I find it convenient when I need to search many things in bulk.
¶Firefox enhancements
I find it convenient to enable 'highlight all' for search within a page.
¶Chrome enhancements
When I used Chrome, one thing that annoyed me was that it populates search engines automatically, and there is not way to disable it.
There is a nice open source extension that prevents Chrome from doing it.
¶7 Searching in code
TLDR: I tried different existing code search tools, was disappointed and ended up using Emacs + Ripgrep.
¶Why?
I've got lots of personal projects, experiments, data processing and backup scripts on my computer. I also tend to create a git repository at a slightest opportunity primarily as a means of code backup/rollback and progress tracking, but often it results in actual projects, so I would need a repository anyway. Naturally, these repositories end up scattered across the whole filesystem, making it tricky to remember where I've put the code or that it even existed in the first place.
It's very convenient to have some sort of code search engine if you're in a similar situation to mine for multiple reasons:
Doing potentially breaking code changes
For instance, I want to remove some unused function or refactor something in
mypackage, which is a Python library to access my personal data. It's used in lots of scripts or dashboards that run in Cron every day.I could just go for it, remove the function and hope nothing fails, but if it does then I'd have to deal with fixing it again. It's frustrating and I'd rather search for function usages in all of my code and make sure it's actually safe to remove.
Reusing code snippets and tricks
When you're getting familiar to some new library or framework, you often end up googling how to solve problems twice. Sometimes you remember solving the problem you've already had, but don't quite recall where.
For instance for me, such library is Sqlalchemy. It's very convenient for handling databases, but I only need it infrequently, so can never remember how to work with it. Reading documentation all over again is not very helpful because I've got very few usecases and queries that are specific to my purposes.
If I can search for
sqlalchemyin my code, it shows every repository where I used it so I can quickly copy bit of code I'm interested at.Forgotten code
It happens that I remember writing code for some purpose, but don't quite recall where I put it. Even if you keep all your repos in the same location, you might forget how you named it.
Full text search, however, allows to find it if you remember some comments or class/function names.
Help and documentation
However good is library's documentation, sometimes it just isn't covering your typical needs. If you're a power user, docs are almost never enough and you end up reading the code to bend the library into doing what you want.
For me such libraries are Org mode or Hakyll, so I often had to search in their code on Github. Searching on Github however is quite awkward. It's slow, it's not incremental and lacks navigation.
If I have a local clone of the repository on my disk, I can search over it in an instant (without having it opened in the first place) and use familiar tools (e.g. IDE) for navigation.
At the time, I was just using recursive grep and then opening some of results in vim to refine.
That's a pretty pathetic workflow.
¶What do I want
My ideal code search tool would:
run against code on my filesystem
Just any source files, so it wouldn't have to fetch repositories from Github and keep them somewhere separately.
realtime indexing
Ideally, inotify-based, but any means of refreshing search index without having to commit first would be nice.
- semantic search in definitions/variables etc with fallback to simple search if the language isn't supported
¶Existing code search tools
So, I wanted some code search and indexing tool that could watch over all the source file on my filesystem and let me search through them.
It sounds as a fairly straightforward wish, but to my surprise, none of existing projects I found and tried do the job:
-
Lets you index Github/Bitbucket/Gitlab repos etc, but the process for adding local repositories is extremely tedious. Also apparently, it clones repositories first so it's not exactly realtime indexing.
Overall, I feel that it only makes sense for companies that use few monorepos.
- OpenGrok: setup looks extremely heavy, doesn't support realtime search in arbitrary paths
- Hound: doesn't support recursive repository discovery.
- zoekt: manual is pretty confusing and also looks tailored for huge standalone repos
- Livegrep: tailored to huge monorepos (see HN discussion)
As you can see, none of these are convenient for searching in personal code.
¶Solution: use Emacs and Ripgrep
Disappointed, I figured that least I could do is at somehow improve my workflow with grep.
So, what are the problems with using grep?
- running it against all of code results in false positives. node_modules, minified javascript, etc., you name it
- you probably want to at least ignore anything that's ignored by
.gitignore
- you probably want to at least ignore anything that's ignored by
- getting bunch of output lines in terminal is not interactive
- you have to repeat the command to refine the results
- you can't quickly navigate to the result, check it and go back
- running it recursively against your filesystem root is ridiculously slow, even if you use an SSD
- you probably want to restrict your search to directories that look like a project (e.g. repositories), and again, exclude files ignored by version control
As it turns out, ripgrep is the tool!
- respects
.gitignorefiles, so by maintaining.gitignoreproperly (e.g. adding node_modules/venv etc) you can make sure you only get meaningful matches when searching for code. - respects
.ignorefiles. Sometimes code has to be under version control, but you don't want it to show up in search (e.g. could happen if you have vendorized code or minified javascript or static html files). In that case you can use.ignorefiles with the same syntax to exclude certain patterns from ripgrep's reach without messing with.gitignore. - it's very fast, both by benchmarks and subjective experiments. You can read more comprehensive benchmarks here.
If you just use ripgrep instead of grep, code search becomes magnitude more pleasant, but it's still not interactive. Long story short, we can use helm in Emacs to achieve interactivity and incremental search.
The only thing that's left is restricting the search to git repositories only.
Ripgrep relies on regexes, so we can't do something like Xpath queries and tell it to only search in directories, that contain .git directory. I ended up using a two step approach:
first,
my/code-targetsreturns all git repositories it can reach frommy/git-repos-search-root.I'm using
fdto go through the disk and collect all candidate git repositories.Even though fd is already ridiculously fast, this step still takes some time, so I'm caching the repositories. Cache is refreshed in the background every five minutes so we don't have to crawl the filesystem every time. That saves me few seconds on every search.
- then,
my/search-codekeybindings invokesripgrepagainst all my directories with code, defined inmy/code-targetsfunction.
So, literally running grep against my code turned out to be a pretty good solution. I've got about 350 repositories and it works in a blink. Note, however, that I'm using SSD.
Ripgrep searches in real files on my disk, so any changes are reflected immediately, which removes the need for indexing (apart from performance concerns if you've got too many files to search in). It would still be nice to avoid unnecessary disk operations, and of course, semantic search would be great, and that is definitely going to require some sort of indexer.
I've got a global keybinding to invoke Emacs with a prompt to search in code, so I can do in in a blink.
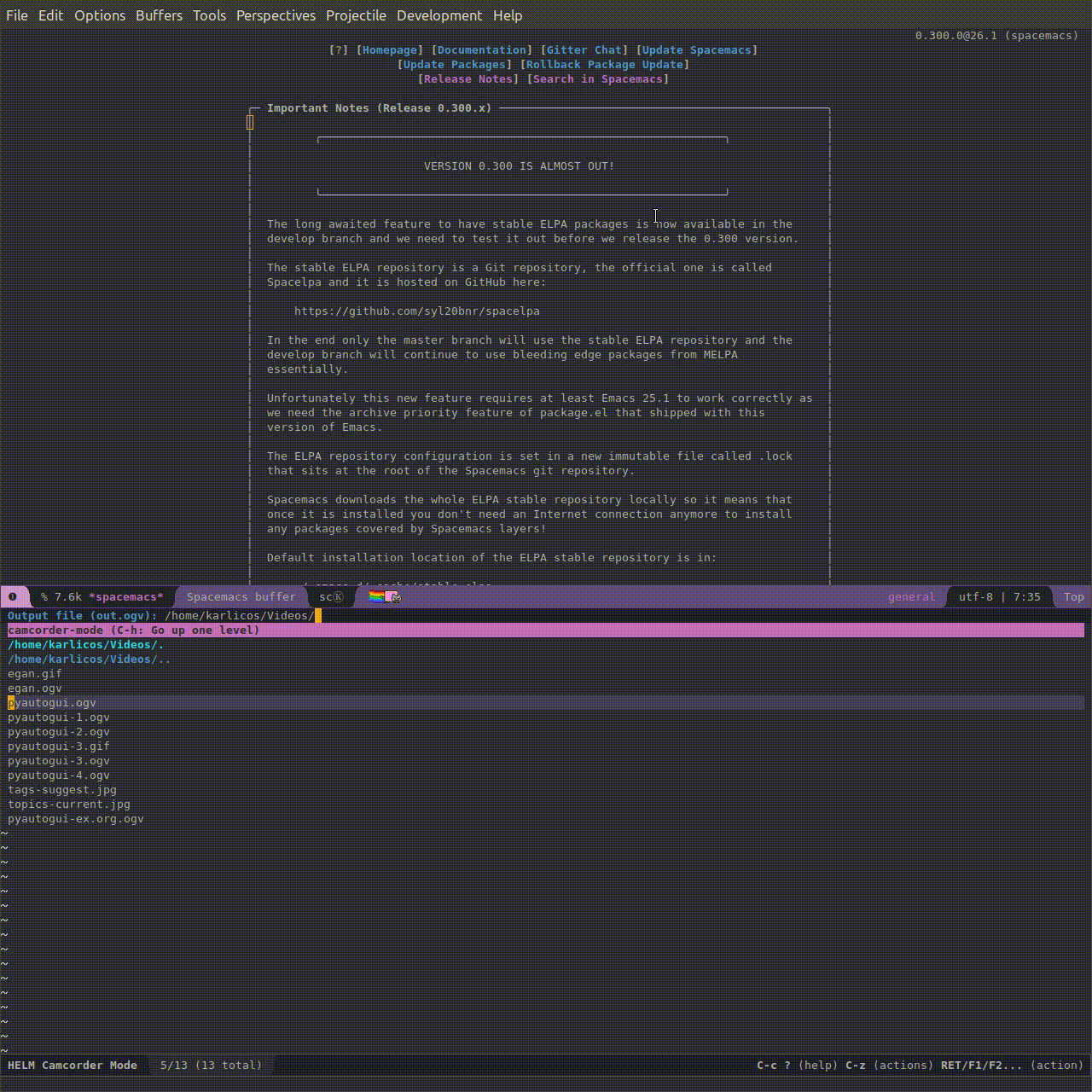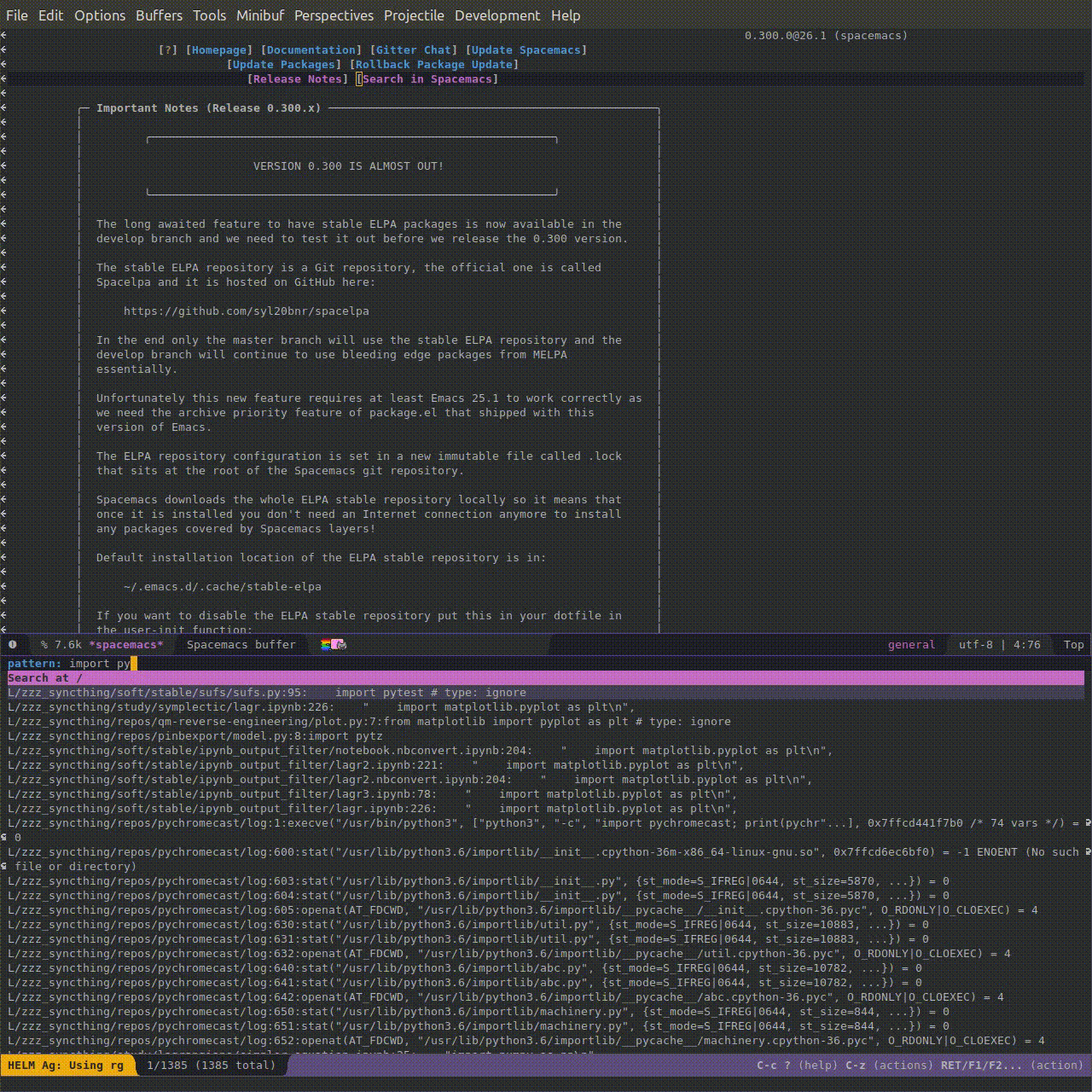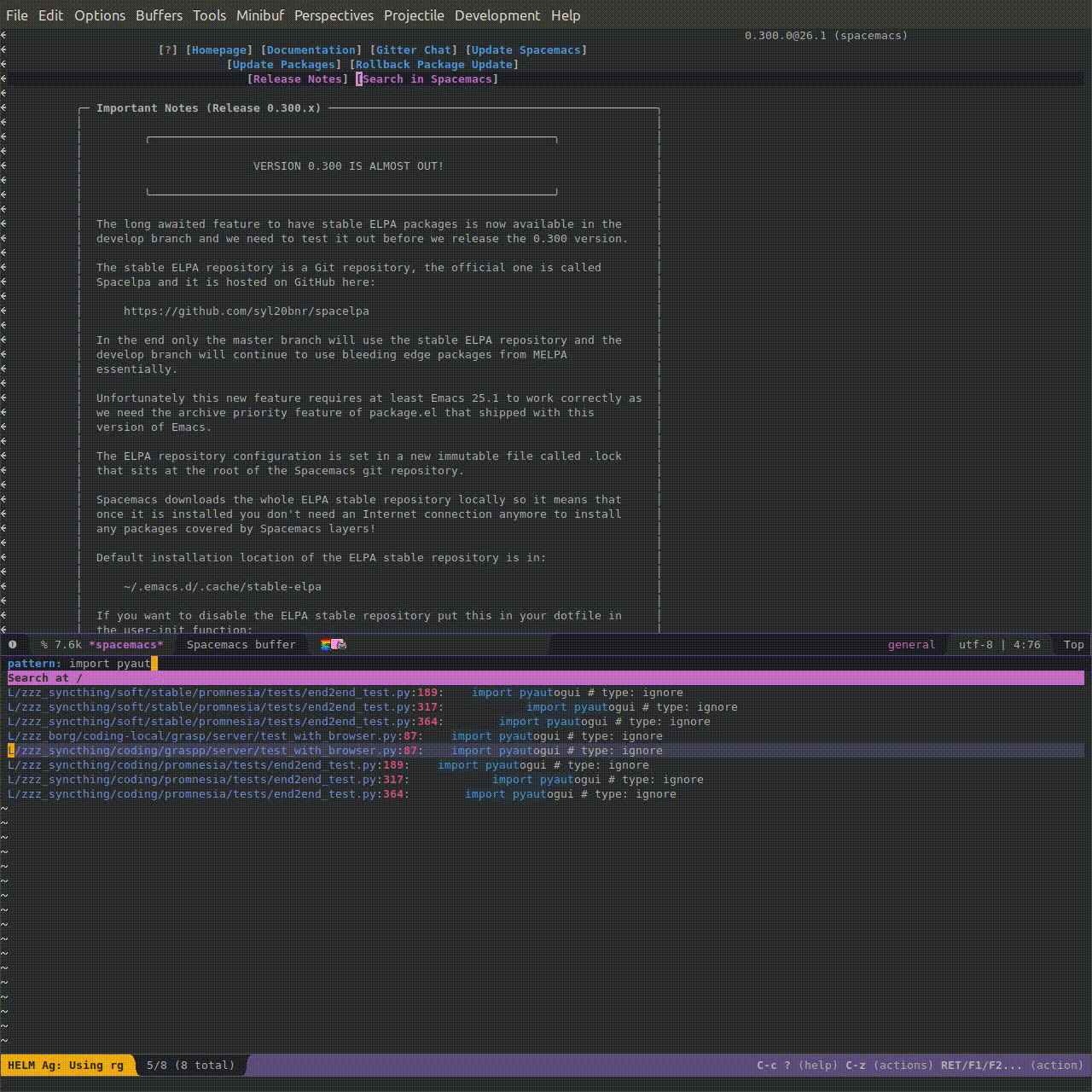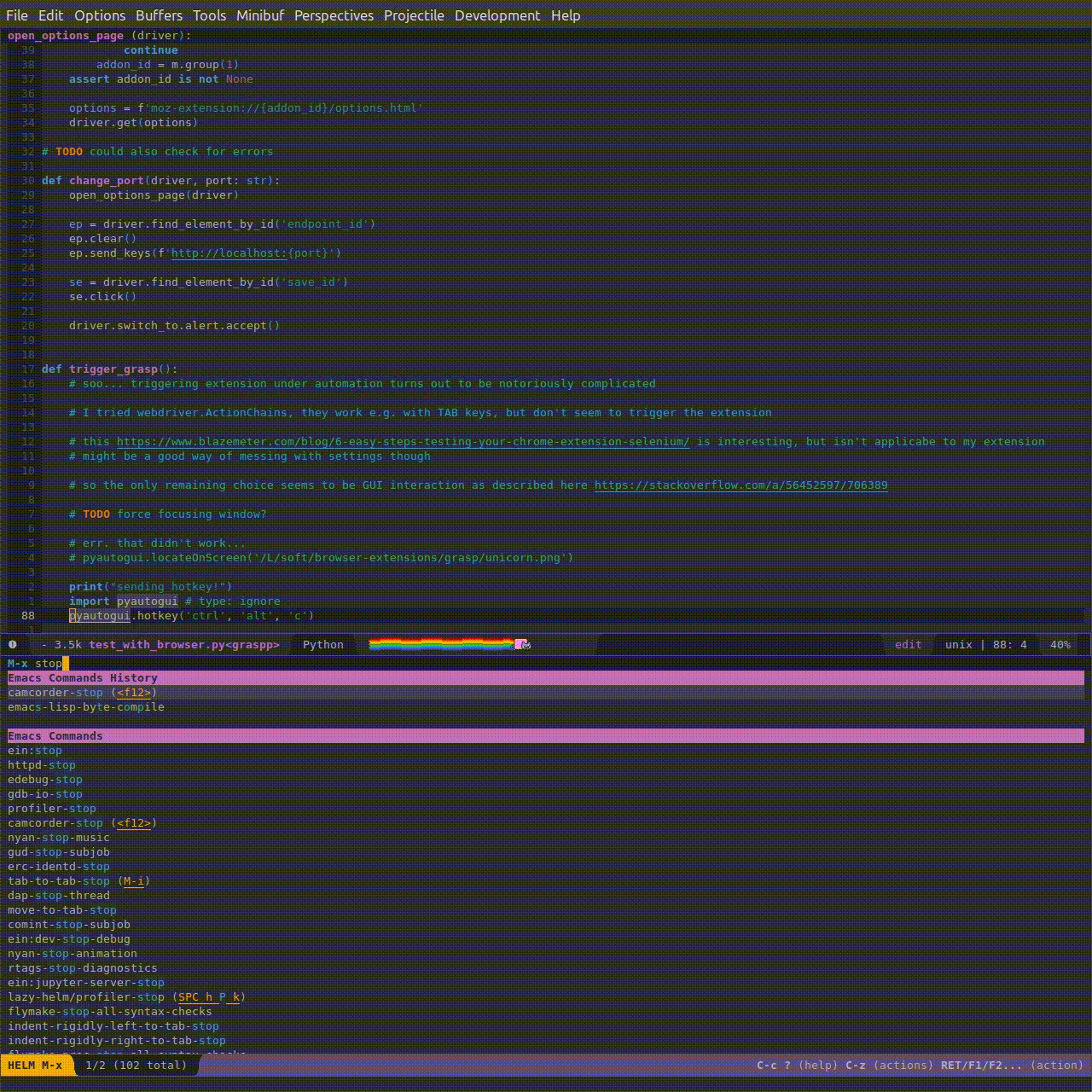
Here's a gif (3.5 Mb) showing it in action: say, I am working on testing a browser extension, and need to interact with in via hotkeys. I remember using pyautogui for automating Grasp tests, but I forgot which function I actually need to use. Searching for 'pyautogui' brings me all the repositories where I'm using it and lets me quickly find out the command I need without having to read the documentation all over again.
{kind=link}
¶8 Appendix: searching away from computer
I'm running Spacemacs on my VPS, so if I'm not near my computer and phone search doesn't help for some reason, I can still access and search my data. You can read about it here.
¶9 Appendix: Lightning fast Emacs
As you might have noticed, I'm relying on Emacs as my primary means of interacting with my information, whether it's capturing, accessing or searching. That means that I want it as fast as possible, in a matter of milliseconds. Seconds spent waiting to launch discourage break your concentration and workflow.
Most of the time I've got Emacs window open on one of my desktops anyway, but sometimes it isn't, or I don't want to pollute the current Emacs instance with my search. So I've got a handy helper script, gemacsclient to quickly invoke a persistent Emacs frame for me.
I've got a global keybinding (Win+m) that invokes this script. In addition the script accepts a function to call so you can open Emacs with a search prompt, so I have few more handy keybindings:
-
Win+F1for searching in my notes and knowledge repository
exec gemacsclient "(my/search)"
exec gemacsclient "(my/search-code)"
Win+ato open my org-mode agenda
exec gemacsclient "(my/switch-to-agenda)"
Win+cto open org-capture
exec gemacsclient "(org-capture)"
running daemon on startup
It might be convenient to always have the emacs daemon running, you can use a method described here to run it via Systemd.
¶10 Appending: general Emacs tips
These tips might be pretty obvious, but they belong to this post, so here you go:
- if you're on Spacemacs, use
developbranch. Master is pretty backwards. search with
ripgrepinstead ofgrep(not only in Emacs!). It's just better.In Spacemacs, set up your
init.el:
dotspacemacs-search-tools '("rg" "ag" "pt" "ack" "grep") dotspacemacs-additional-packages '(helm-rg)
use
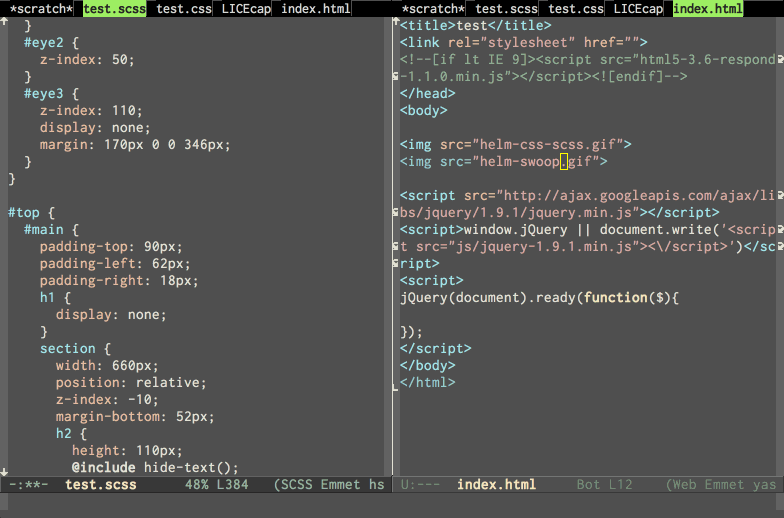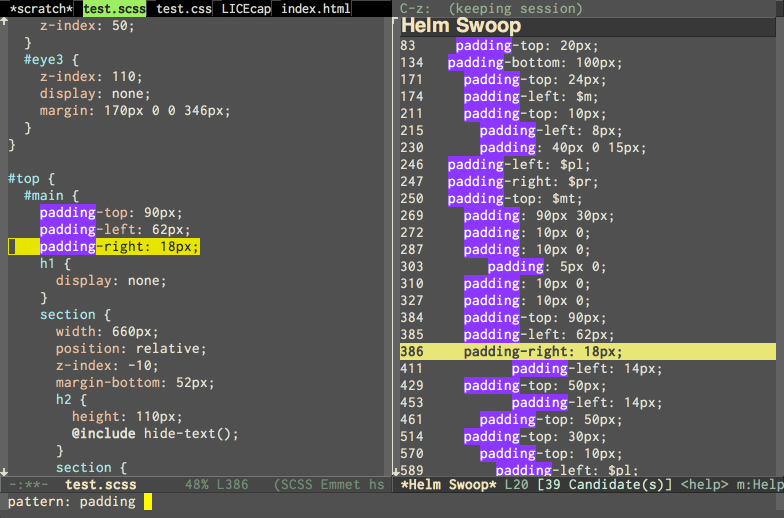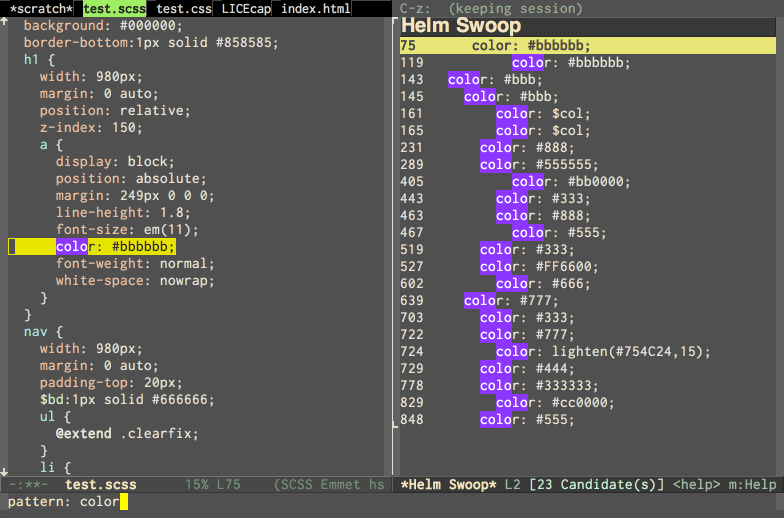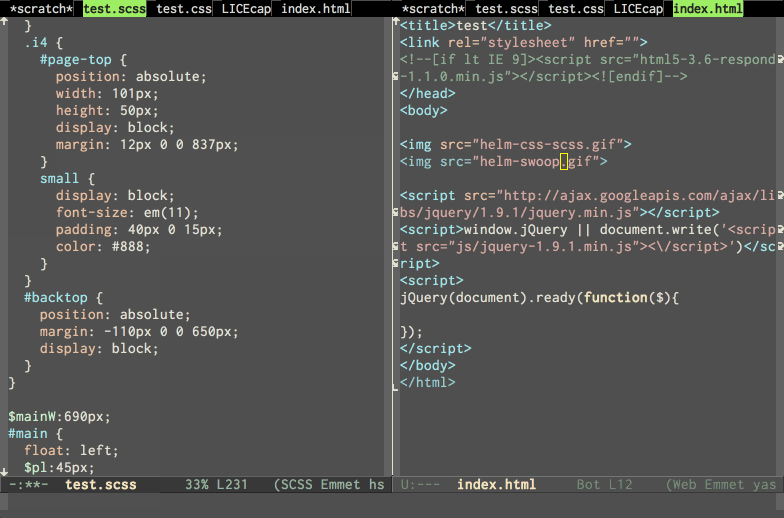
helm-swoopfor search within the bufferIt's easier to watch a demo GIF than to explain. Swoop opens a Helm window with search result summary and jumps between results in the original buffer as you navigate in helm (
C-j/C-k).I highly recommend it as a primary way of searching withing a buffer. Bind it it to some convenient combination and get used to it (e.g. mine is
SPC RET).There is also
helm-occur, which has similar functionality, but it seems inferior to swoop.use
helm-follow-mode(C-c C-fin Helm buffer) to jump between search results in any Helm searchE.g. you can use it with
helm-org-in-buffer-headingsas a neat way to navigate within an Org file.
{kind=link}
¶11 Future and my holy grail of search
My ultimate goal is to have my 'external' knowledge as highly integrated as possible, as if it was imprinted on my brain neurons.
Ideally I want to be able to do fulltext realtime search over anything that I ever had in my visual field. Not even necessarily text, but audio and video as well.
That way one wouldn't have to distinguish between different services and mediums of information at all, be it digital or analogue.
Technically it's not impossible with the current technology:
- I believe that state of OCR is pretty good considering existence of products like google instant translate
- speech recognition still sucks in noisy environments, but generally works
- object recognition and annotation is still at dawn (I think?), but we'll get there eventually
- that would be a lot of data, but potentially lots of it can be filtered out (at least until storage gets really compact and cheap to justify keeping everything)
- processing and indexing don't have to be realtime as you can still rely on biological memory and could work overnight on expensive (but not astronomically so?) hardware
- plaintext indexes can potentially be stored on your phone and you could have some sort of backend to access visual component
- to jump back to the content digital media (like e-books/web pages/information screens) could aid this by supplying QR code or something similar
However each of these is a pretty hard problem and hardly with high demand from people.
Considering Google Glass hasn't made it, the technology is not exactly there, so we have to rely on kludges like the ones I described above.
¶12 --
My closing tips would be:
start simple
It's better to have a crappy adhoc script or bash alias that runs
grepover your ~/notes directory than no means of searching at all.keep your things as plaintext as possible
This is a somewhat sad advice to give in 2019, but the reality is it's still extremely tedious to work with anything else.
whichever tools you use, make sure they launch in an instant
Seconds wasted on waiting break your flow. Better spend time on setting it up once and never think about that later.
give Emacs a try
I feel almost sorry advocating Emacs for everything, but despite my disgust at Elisp and frequent frustration, it just happens to be superior in terms of bending it to do what you want it to.
As always, I'm open to feedback and would love to hear what is or setup or help you if you're struggling with something!